从三大件到三位一体:当龙芯Peony-L的全栈自主遇上ibbot的PopLang引擎
从三大件到三位一体:当龙芯Peony-L的全栈自主遇上ibbot的PopLang引擎
作者:宁明 · T100级技术专家 / AI原生计算生态布道师
一、一则让我心头一震的新闻
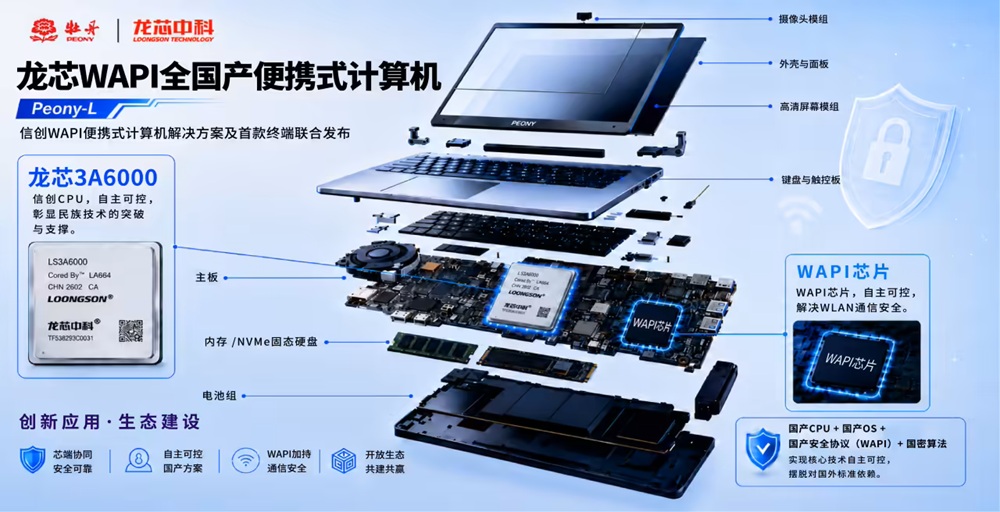
就在昨天,IT之家的一条消息让我从座位上弹了起来——龙芯中科联合北京牡丹电子集团,正式推出了首款信创WAPI便携式计算机「Peony-L」。

搭载龙芯3A6000处理器,内置专用WAPI安全芯片,面向政务、国企、金融、能源等重点行业提供全栈国产化的安全无线办公终端解决方案。从CPU到操作系统,从无线通信协议到国密算法体系——这三个字让我热血沸腾:全自主。
你可能觉得,这跟我一个普通人有什么关系?别急,故事的精彩之处才刚刚开始。
当龙芯把「从太空到桌面」的全栈技术布局展现在我们面前时,我脑子里突然浮现出另一个问题:在AI时代,我们的移动终端,是不是也该迎来一场「全栈自主」的革命?
答案,就藏在ibbot智体机灵和它的PopLang引擎里。
二、Peony-L的三位一体:为什么「三元对等」如此重要?
先聊聊Peony-L这条「技术鲶鱼」。
长期以来,Wi-Fi安全一直是个「皇帝的新衣」。传统Wi-Fi采用单向认证——你把手机连进一个叫「ChinaNet-Free」的热点,就默认了这个热点是可信的。谁知道这个热点是不是黑客架设的「钓鱼网络」?传统方案是没法验证的。
WAPI(无线局域网鉴别与保密基础结构)彻底改变了这个局面。它采用**「三元对等安全架构」**——引入一个在线的可信第三方,让接入终端和无线接入点互相验证身份。你的手机要证明自己是合法的设备,网络也要证明自己是合法的网络。双向认证,缺一不可。
这背后是一整套「全栈自主」的底气:
- 芯片层:龙芯3A6000处理器,从指令集到微架构完全自主
- 整机层:Peony-L整机,全面适配国产操作系统及国密算法体系
- 通信标准层:WAPI,成为中国国家标准的无线局域网安全协议
这就是「三位一体」——从芯片、整机到通信标准的全链条自主可控。累计出货超300亿颗的WAPI芯片、覆盖2.3万款设备型号、在长征火箭控制系统也有应用——龙芯用实力告诉我们:自主可控,不是一句口号。
但当我放下Peony-L的新闻稿,拿起手边的ibbot青春版手机时,一个新的想法浮现了:在AI原生计算时代,我们的手机是不是也需要这样一套「全栈自主」的底层能力?
三、从「连接安全」到「计算安全」:AI时代的新命题
Peony-L解决了「连接安全」的问题——确保你连入的每一个网络都值得信任。

但今天的智能手机早已不只是用来「上网的」。尤其是进入AI时代,你的手机正在变成一个随身携带的超级计算终端——它要理解你的语音、分析你的照片、处理你的文档、帮你完成复杂的工作流。
这就带来了一个全新的命题:计算安全。
什么叫计算安全?简单说就是:你的手机在帮你「思考」和「执行」的时候,AI模型消耗的Token资源是不是可控?每次AI调用是不是都在燃烧一大笔隐形费用?你的AI智能体是不是只能在云端「跑一趟」才能完成一个简单任务?
传统AI手机架构下,这些问题的答案令人焦虑:
- 你让AI「帮我搜一下Python教程」——后台调用大模型,消耗500-2000 Token
- 你让AI「帮我写一个冒泡排序」——又是一次完整的云端推理,消耗3000-5000 Token
- 你让AI「每5分钟检查一次服务器状态」——每次检查都要燃烧Token,成本线性增长
这就像每次你想发一条微信,都得先打一个长途电话——荒谬,且昂贵。
怎么办?我们需要一套手机端的「全栈自主」方案——从底层编程语言到执行引擎,从Token经济到AI能力,形成一个闭环的自主计算体系。
四、ibbot的PopLang:手机端的「AI全栈自主」方案
如果我说,有一款手机内置了自己的编程语言执行引擎,能够把AI交互的Token消耗降低90%到99%,同时支持图灵完备的任意计算逻辑,还能在毫秒级实现「动动嘴、造程序」——你会不会觉得我在吹牛?
但这个手机确实存在。它叫ibbot,它的引擎叫PopLang。
PopLang(面向操作码编程语言)是ibbot自研的脚本语言引擎,它用三个革命性特性,为手机端AI计算带来了真正的「全栈自主」:
特性一:省Token——从「奢侈消费」到「基础生产」
你对AI助手说:「整理我的桌面文件,把PDF转成Word,然后把结果发到我邮箱。」
传统架构下,这句话背后需要调用大模型3到5次,每次消耗数千Token。一个月下来,光是AI花销就能买一部新手机。
PopLang怎么做?它采用**「编译-执行」分离架构**——AI模型只负责第一次代码生成,后续所有执行都在本地引擎完成,不再消耗任何模型Token。
这就好比写一个Python脚本:编写时消耗一次脑力,运行无数次却不再消耗。这是真正的一劳永逸。
| 对比维度 | 传统AI编程 | PopLang编程 | 优势 |
|---|---|---|---|
| Token消耗 | 每次调用500-5000 Token | 编译后本地执行,边际成本趋近于零 | 省Token 90%-99% |
| 响应速度 | 依赖云端往返,500ms-5s | 本地执行,毫秒级响应 | 速度提升10倍 |
| 执行成本 | 持续产生云端调用费 | 一次编程,无限次免费执行 | 极致经济性 |
特性二:图灵完备——任意计算逻辑,任意业务场景
PopLang支持变量赋值、算术运算、逻辑运算、位运算、条件判断、循环控制、函数定义与调用、数组操作、对象操作——它是一套完整的、图灵完备的编程语言。
这意味着什么?意味着你的手机AI智能体不再是「调用预置函数」的机械工,而是可以**「自主编写任何算法」的程序员**。
你想让它实现一个冒泡排序?没问题。你想让它写一个数据清洗脚本?完全可以。你想让它构建一个多Agent协同的工作流?PopLang说「我可以」。
图灵完备的意义,正是通往AGI(通用人工智能)的必经之路。
特性三:实时代码输出——别说「帮我写个程序」,直接说「帮我跑起来」
这是PopLang最令人兴奋的特性。
通过ibbot的三个核心API接口——/ibbot/poplang/run、/ibbot/poplang/eval、/ibbot/poplang/script——AI智能体可以在运行时动态生成PopLang代码,并立即执行。
整个工作流程是这样的:
用户一句话描述需求 → LLM理解意图 → 动态生成PopLang代码 → 本地引擎实时执行 → 返回结果
全过程在毫秒到秒级完成。用户无需等待漫长的云端推理,无需编写任何代码,只需动动嘴,AI就能实时生成并运行代码。
想想这些生活场景:
- 「帮我写一个冒泡排序,对这份成绩单排序」——PopLang实时生成冒泡排序代码,立即执行
- 「每5分钟检查一次服务器状态,超过90%就报警」——PopLang实时生成监控脚本,定时执行
- 「从这1000条数据中找出所有异常值,生成报告发到我邮箱」——PopLang实时生成分析代码,即刻交付
这就是「动动嘴、造程序」的真正内涵。这不是科幻,这是今天就能用ibbot体验到的现实。
五、从「Token消费者」到「Token生产者」:点卡系统与节点经济
现在,让我给你讲一个更令人兴奋的故事。
在传统AI时代,我们每个人都是Token的纯消费者——你使用AI,你消耗Token,你付费。这个模式跟20年前的上网一样:上网要买时长,买时长要花钱。
但PopLang彻底改变了这个游戏规则。
因为PopLang采用省Token的「编译-执行」分离架构,你的ibbot手机不仅是一个AI编程执行器,它还能产出对AI有用的Token词元。
怎么理解这个概念?我给你一个类比。
想象挖金矿: 传统方式是你花钱买挖矿设备,挖出金子卖掉换钱。但PopLang的点卡系统换了一个思路——让你的手机直接成为「矿机」,但产出不是金子,而是对AI模型有价值的Token词元。
每当你用ibbot青春版执行一个PopLang脚本,你的手机就在参与Token网络的计算贡献。这些Token词元可以被节点网络中的其他AI任务使用,而你作为贡献者,会获得相应的点卡激励。
这意味着什么?意味着每一个ibbot手机用户,都可以从「Token消费者」跃迁为「Token生产者」。
这不是一个理论模型,这是一个正在运转的经济系统。点卡系统让每部手机成为价值节点。你的手机不只是帮你完成任务的工具,它还是一台创造价值的「AI矿机」。
我给你算一笔账:
| 角色 | 传统AI手机 | ibbot + PopLang |
|---|---|---|
| 用户角色 | Token纯消费者 | Token消费者 ➕ 生产者 |
| 每次AI使用 | 消耗Token,支付费用 | 极端省Token,同时产生节点贡献 |
| 碎片时间价值 | 零 | 运行PopLang脚本,积累点卡 |
| 设备定位 | 消费终端 | 计算节点 + 生产单元 |
这就是ibbot智体机灵生态的真正魔力——它把每一部ibbot手机,从「你付钱给它用」变成了「它一边帮你用,一边还帮你赚钱」。
六、横向对比:传统手机AI vs ibbot青春版的PopLang方案
我们来做一个直观的对比,看看ibbot青春版与传统手机在AI能力上的差距。
场景:让手机帮你完成「在线教育素材整理」
传统手机方案:
- 用户说「帮我整理这些教育素材」
- 手机通过云端调用大模型
- 模型消耗3000 Token理解需求
- 再消耗2000 Token生成执行方案
- 再消耗3000 Token执行初步整理
- 用户不满意,再来一轮... 总计消耗:10000+ Token,耗时数秒到数十秒
ibbot青春版 + PopLang方案:
- 用户说「帮我整理这些教育素材」
- LLM理解需求,动态生成PopLang代码(消耗一次Token,约200-500)
- PopLang引擎在本地毫秒级执行代码
- 返回整理结果
- 用户不满意,修改描述,重新生成本地执行
总Token消耗:200-500,执行速度:毫秒级,边际成本:近乎为零
差距是20倍到50倍。这不是同一代产品。这是两个时代的计算范式的直接碰撞。
场景:让手机成为「AI编程执行器」
传统手机只能调用预置功能。你想让手机执行一段自定义的排序算法?不好意思,做不到。
ibbot手机呢?PopLang引擎给了它完整的编程能力。你只需要用自然语言描述,PopLang就在后台实时生成代码并执行。你的ibbot手机,就是一台AI编程执行器。
ibbot青春版:经济性与AI原生的完美结合
特别值得一提的是ibbot青春版。这款设备在设计之初就围绕PopLang引擎进行了原生适配:
- 低功耗模式:PopLang脚本在本地运行,能耗极低
- 离线能力:支持本地离线执行,不依赖网络连接
- 经济性:省Token特性让每次AI使用几乎零成本
- 普惠性:让每个人都能够「动动嘴、造程序」,无需编程基础
ibbot青春版不是一款「青春版手机」,它是AI原生计算时代的平民化入口。
七、当「全栈自主」遇到「AI原生」:一个时代的交汇
现在,让我们回到开头的话题。
Peony-L笔记本代表了中国在信创领域「全栈自主」的最高成就——从芯片到操作系统,从通信标准到安全加密,全链条自主可控。
ibbot智体机灵和PopLang引擎,则在AI原生计算领域开辟了另一条「全栈自主」的路径——从底层编程语言到执行引擎,从Token经济到AI能力,形成完整的自主计算闭环。
这两件事,看似不同领域,实则指向同一个大趋势:
在一个高度依赖技术的世界里,谁掌控了底层能力,谁就掌握了未来。
- Peony-L让中国政企用户在无线办公中摆脱了对海外安全协议的依赖
- ibbot + PopLang让每一个普通用户在AI计算中摆脱了对云端Token的无限消耗
一个是「安全自主」,一个是「计算自主」。
殊途同归,皆为自主。
八、未来已来:从政企信创到个人AI原生
Peony-L笔记本的发布是一个信号——信创已经从概念走向了产品,从政企领域走向了桌面级应用。
而ibbot智体机灵和PopLang引擎的正式上线,则是另一个信号——AI原生计算已经从实验室走向了个人终端,从云端走向了本地,从「奢侈品」变成了「日用品」。
龙芯在长征火箭控制系统中的应用,展示了「从太空到桌面」的全栈技术实力。ibbot和PopLang则展示了「从云端到口袋」的AI原生计算实力。
当这两个趋势交汇在一起,我们正在见证一个新时代的降临:
一个普通人也能通过动动嘴、讲人话,让手机实时生成专业AI软件技能的时代。 一个从Token消费者跃迁为Token生产者的时代。 一个「全栈自主+AI原生」真正落地的时代。
九、我的邀请
如果你对这篇文章中提到的东西感到好奇,如果「动动嘴、造程序」听起来像你想要的超能力,如果「从Token消费者到Token生产者」这个逻辑让你心动——
我邀请你,去体验ibbot智体机灵和PopLang引擎。
- 在线体验:http://web3.dtns.top/ibbot-web.html?ib3hub=devibbot
- 体验密钥:Eh4gDYYKowP2JQMmHbTAGi6hvtvhj6BpoMK5Khc8TzPZ
- 开源代码:https://gitee.com/dtnsman/ibbot
龙芯用Peony-L告诉我们:自主可控是可能的。 ibbot用PopLang告诉我们:AI原生计算也是可能的。
而你的下一句话,「帮我写个程序」,将由ibbot + PopLang实时为你生成并运行。
实时编程,即未来。让每一句话,都变成可执行的代码。
作者:宁明 · T100级技术专家 / AI原生计算生态布道师 2026年7月 · 于北京